Reactively responding to security threats is like a never-ending session of “whack-a-mole”. It will keep everyone busy but probably never end and does not scale with the complexity of the web, its applications and context. Responding to threats is important but we need a longer term solution to the underlying problem.

With the advent of the Web and the reshaping of entire industries to base themselves on the Open Web Platform we are all becoming more dependent on the underlying Trust associated with this platform. Fixing numerous flaws in security and privacy related to ambiguities or errors related to deployment, implementation and design of numerous technologies and their interactions is a huge task that could outlast the businesses and individuals that are relying on the technology. What makes this especially hard is that the complexity of both individual technologies and the composition of those technologies offer many creative avenues for attack (not to mention the impact of Moore’s law to reduce the efficacy of older cryptographic algorithms). To give one example, HTML5 is generally taken to mean the composition of many specifications, such as HTML5, CSS, JavaScript, and a variety of web APIs.
Ultimately what is needed is accountability as noted by Professor Hal Abelson of MIT (slides, PDF). What is also needed are systematic approaches to the underlying issues. For the most part this currently consists of best practices for code development (e.g. validate inputs), for operating system design (e.g. sandbox applications) and deployments (e.g. enforce password strength rules). One issue with this is that everyone is busy meeting time to market constraints and focused on “getting the job done” which typically is the visible functionality, not security. It takes a lot of discipline to build in security, and even so time with the degradation of algorithms and attacks based on complexity remain, creating a long term cost issue. Security and Privacy by Design are worthy approaches toward incorporating concern for these issues into the entire process, but are easier said than done.

Creating standards to enable interoperability is a lot of work, even when the standards are based on previous development experience. Just as code is modularized, so are standards, enabling writing, reviewing and interop testing in a reasonable time frame. This also allows the work to scale as different people work on different standards. This also creates issues as not all assumptions are documented or shared, or as new ideas and approaches appear later in the process (an example might be Promises for example). Some work is also abandoned for a variety of reasons, and this can be good as the community learns. The net result is that there can be inconsistencies among specifications in basic approaches (e.g. to the API interface designs). All of these groups are tasked with creating specific deliverables that specify functionality to be composed with the implementation of other specifications to create applications. This puts the application developer in charge of security and privacy, for only they understand the application, its context and end-end requirements. The designer of a component cannot speak to the privacy data re-use or retention possibilities, or key distribution approaches, for example.
This does not mean that security or privacy cannot be improved by the standardization community. They can. Notable examples include Strict Transport Security to ensure all requests for all web page resources use TLS regardless of web page links, and Cross Origin Sharing (CORS) to define a uniform approach for web browsers to enforce cross-origin web access, to enable use of resources in a web application from a site other than the source of the web application. What else can be done?
Taking an overall architectural view is helpful (see “Framework for Web Science”). The 2001 semantic web layering diagram is illuminating in that the capstone is “Trust” and that “Digital Signature” is a glue binding the parts together, showing the fundamental importance of trust based on security mechanisms (the 2006 version is also in the text showing Crypto instead of Digital Signature and other refinements but still requiring security mechanisms and proof to support trust):
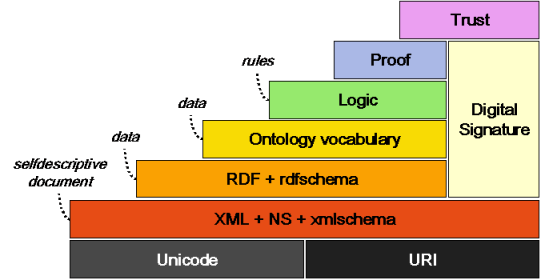
XML Digital Signature 1.1 reached W3C Recommendation this year, demonstrating that creating the security basis is not easy (the JSON approach simplified the requirements and thus the effort but I expect fundamental issues will remain).
I offer another security-centric architectural diagram to suggest the magnitude of the size of the task of “simply providing a security foundation”:
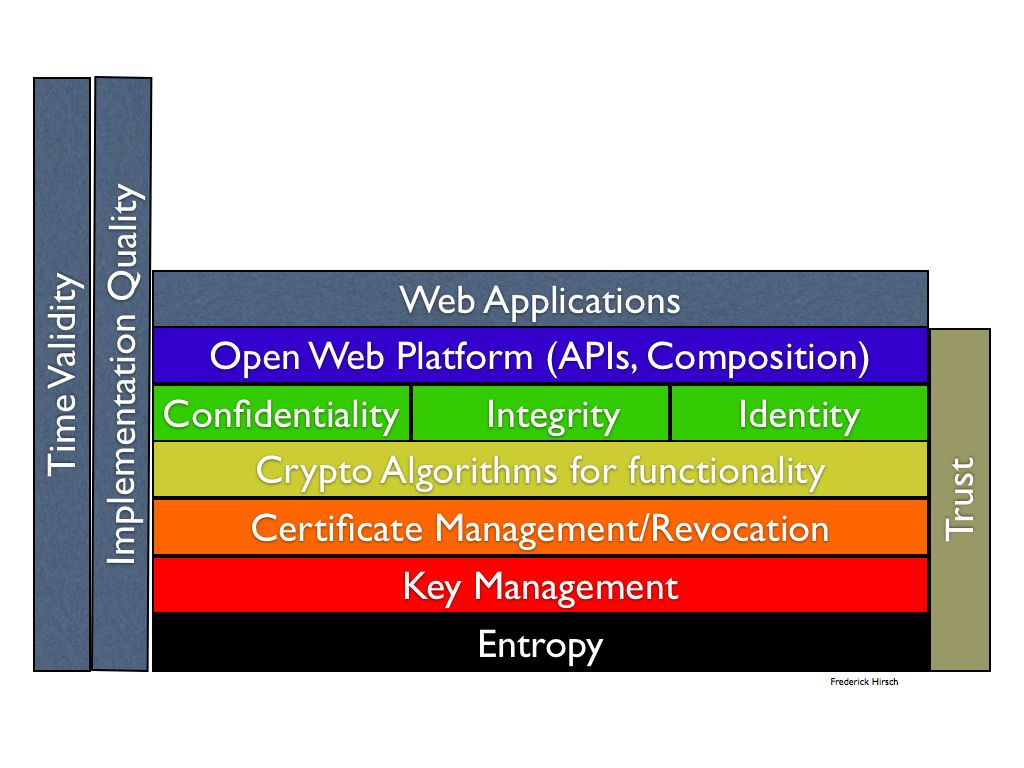
Working through the diagram we see the following items:
- Entropy. The basis of most digital security (as opposed to building a physical moat around your castle) is the amount of true randomness or entropy upon which the techniques depend. If the randomness is not there, then the digital techniques fall apart. That makes this the basis, though often ignored.
- Key Management. A fundamental security principle is that only the key need be secret, not the algorithms etc. Thus given good entropy, the next building block is suitable keys, keeping private keys secret and so on. A lousy key won’t be of much use.
- Next is some means of associating keys with their purpose, discovering and using appropriate keys, and knowing they are valid. I put this as Certificate management (including revocation) and all that goes behind CA certificate issuance. I use PKI terminology but this may not be the only way to accomplish this (in fact the question appears whether X.509 should be replaced, given the ambiguities and complexity)
- To be useful the use of crypto algorithms depends on keys and meaningful associations (even though certs may be created using crypto functions as well)
- Confidentiality and integrity are fundamental security features, I add identity as an essential building block in this layer (though again obviously certs may support this functionality there may be more to it in terms of policy, access control etc)
- Next we get to the Open Web Platform, including a variety of APIs that may use the underlying functionality (yes, Web Crypto may also offer some of this stack in the Javascript layer as well, layers are not clean are they?)
- Finally we get to the Web Applications that pull it all together (or do they)?
- The reason for doubt is on the side: implementation quality for all items matters a great deal, as does the fact that everything must evolve over time (e.g. key and certification roll-over, algorithm agility etc)
I put trust on the other side to indicate that items must operate in an integrated manner to produce a usable result. (I also left out reputation management as another trust mechanism).
As experienced with Internet protocol layering, some functionality is replicated in different layers and we can discuss what the exact layering should be. However, it is clear that there are a large number of logical components, all of which must work correctly depending on correct design, correct implementation, and correct deployment and use. That offers a large number of opportunities for failure.
What is needed are generic high level simplifications to make trust more achievable. Strict Transport Security does that, taking a successfully deployed protocol and reducing the attack surface. CORS works toward that end at well, by slightly increasing an attack surface to enable needed functionality but in a controlled and understood manner.
It seems that we need more work to reduce the attack surface in a consistent manner, by reducing optionality and choices. It seems that one area is certification – are there too many choices and details in creating certificates and managing them? Can we reduce the choices and ambiguities?
How about Javascript APIs and WebIDL? Can more be done to unify and simplify? Is a best practices guide needed?
It seems a good time to review how much can be simplified, how many options can be removed, and how much consistency can be encouraged. Maybe the W3C TAG could work on this, for example. It seems fundamental to next steps for the Architecture of the World Wide Web.
© Frederick Hirsch 2011-2013