We’ve just published an update to our previous IoT Security Maturity Model (SMM) 62443 mappings publication, adding the service provider role. Please see the press release for some details and the previous blog post for an introduction.
This joint work of the Industry IoT Consortium (IIC) and the International Society of Automation (ISA) extends the previous work to complete the mappings.
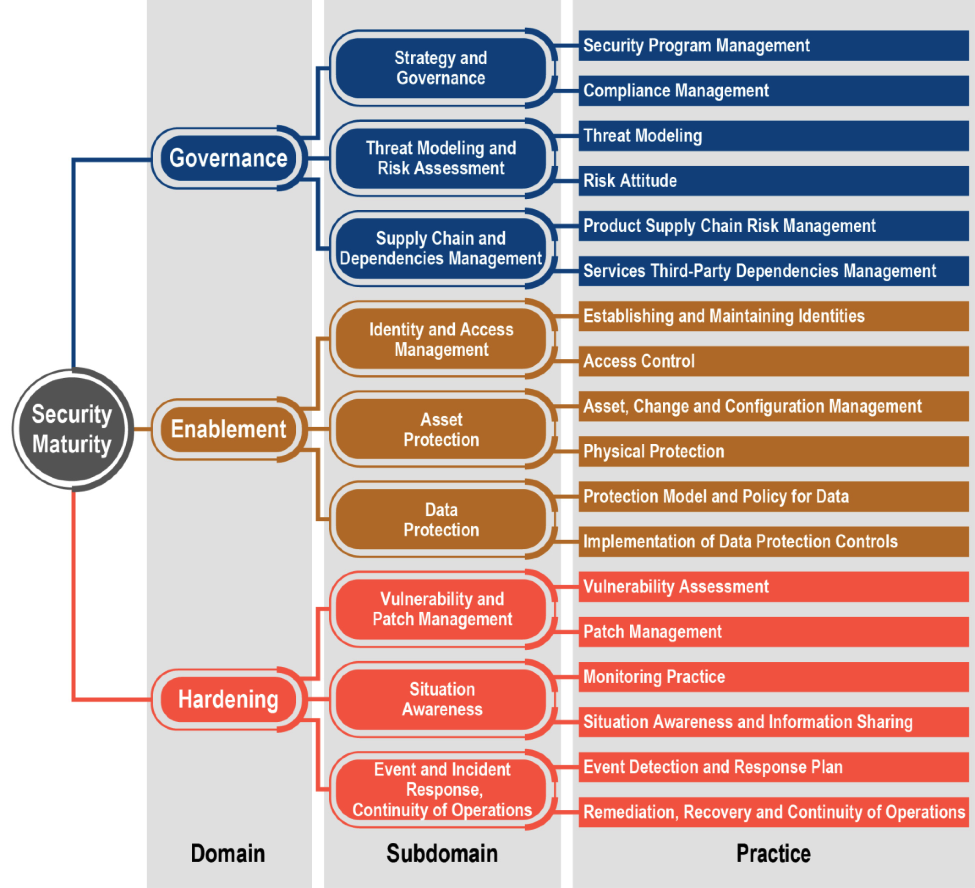
This document extends our previously published technical report, the IoT Security Maturity Model (SMM): Practitioner’s Guide. That document describes the principles and process for setting targets and assessments for security maturity, breaking down the expanse of security concerns into eighteen practices in the three domains of governance, enablement and hardening. These practices include governance, technical and non-technical controls and operational aspects. This is shown in the following diagram from the Practitioner’s Guide:
SMM Domains, Subdomains and Practices
Each practice description gives information and guidance on the four comprehensiveness levels of minimum (1) , ad hoc (2), consistent (3) and formalized (4) with descriptions of each, including what needs to be done to achieve the level, and indicators of accomplishment (useful for assessments). A key idea is that unlike other maturity models, higher levels are not necessarily better. Rather, the appropriate comprehensiveness level for each practice should be chosen to match the need, limiting investment to what is required and makes sense.
The SMM is designed to be extensible, with profiles that expand the scope to industry or system specifics, and with mappings that relate the guidance to other frameworks and requirements.
SMM Extensibility with Profiles and Mappings
Profiles are one way of extending the SMM Security Maturity Model. While the practitioner’s guide describes the general case, or general scope, it also permits guidance appropriate to industry or system specific scope to be added to the general guidance. For example, we have previously published in collaboration with the OMG the IoT SMM: Retail Profile for Point-of-Sale Devices offering additional guidance relevant to retail. It includes industry scope level guidance, such as using Data Security Standard (PCI-DSS), Payment Application Data Security Standard (PA- DSS), and the PIN Transaction Security Devices (PTS) to achieve the consistent comprehensiveness level (level 3) for the compliance management practice, to give an example. It also includes device scope guidance for the compliance management level 3 with the requirement to ensure compliance with PIN Transaction Security Devices.
Another way of extending the SMM is with mappings. This newest publication is a set of mappings to the 62443 standards. This provides a linkage between the guidance for a specific comprehensiveness level in a practice to related 62443 requirements. One way to use this is to determine the maturity target, setting comprehensiveness levels for each practice using the Practitioner’s Guide for guidance. Once this is done then the mappings for the appropriate comprehensiveness levels (and the lower ones which must also be met to achieve a comprehensiveness level) can be used to review the appropriate 62443 requirements.
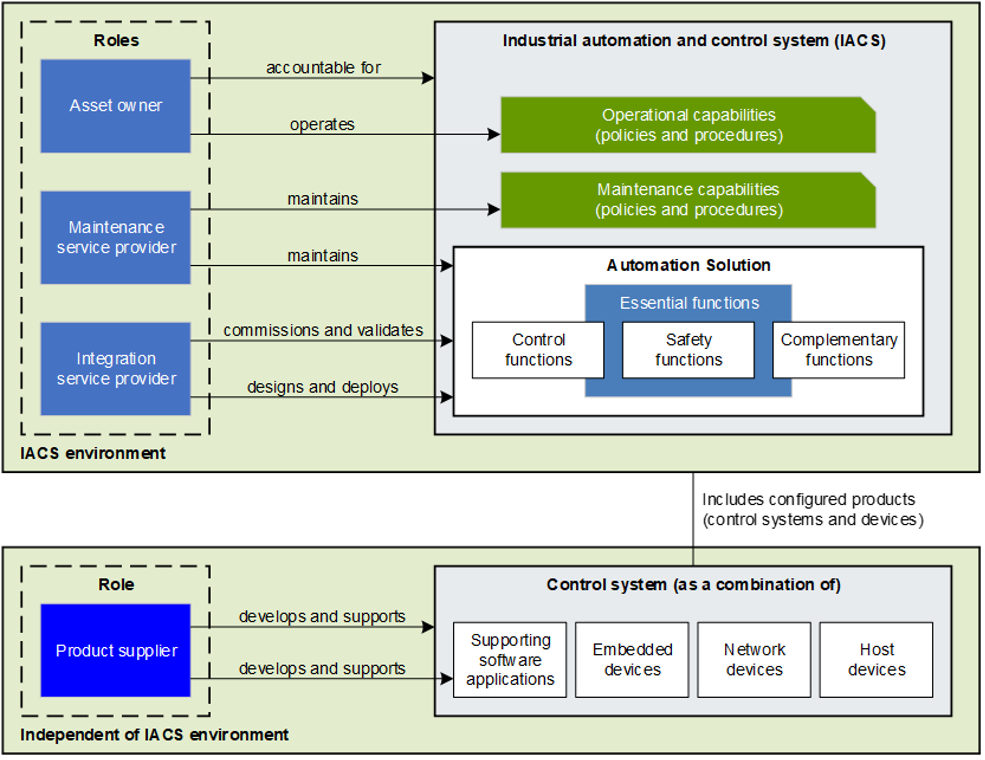
The current 62443 mappings focus on the needs of Asset Owners and Product Suppliers as defined in that document, a subsequent revision will add service providers. The following diagram from the mappings publication (derived from ISA documentation) shows the roles:
Roles in 62443
We are working on a later update to add Service Providers to the mappings document.
This Security Maturity Model (SMM) provides a way of understanding the areas that impact security maturity by structuring the practices into the domains of governance, enablement, and hardening (think of governance, security by design and secure operations). Subdomains structure this more finely, into topics such as security program management, threat modeling, establishing and maintaining identities, physical protection, patch management and monitoring practice, to name only a few of the eighteen practices described in the Security Maturity Model (SMM) Practitioner’s Guide.
The Security Maturity Model (SMM) has a table for each of the 18 practices defining objectives, and the description, actions and indicators of accomplishment for the various maturity levels. These include minimum (1), ad hoc (2), consistent (3) and formalized (4). Importantly the model does not assume that a higher number is better, but rather describes a process toward achieving the right match to the needs and situation. The model also allows for extensibility to provide guidance for an industry or system, when appropriate to go beyond the general guidance. An example (to discuss in a different blog post) is the IoT SMM: Retail Profile for Point-of-Sale Devices which was developed jointly by the IIC SMM team and the OMG Retail Task Group.
There is much more to the IIC IoT Security Maturity Model (SMM) Practitioner’s Guide, such as discussion of the process of setting targets and performing an assessment.
This new version of the SMM improves the clarity and usefulness of the Practitioner’s Guide by adding new guidance to the numerous practice tables, clarifying scoring and the case studies, correcting minor errors and incorporating reader feedback, all without changing the underlying model.
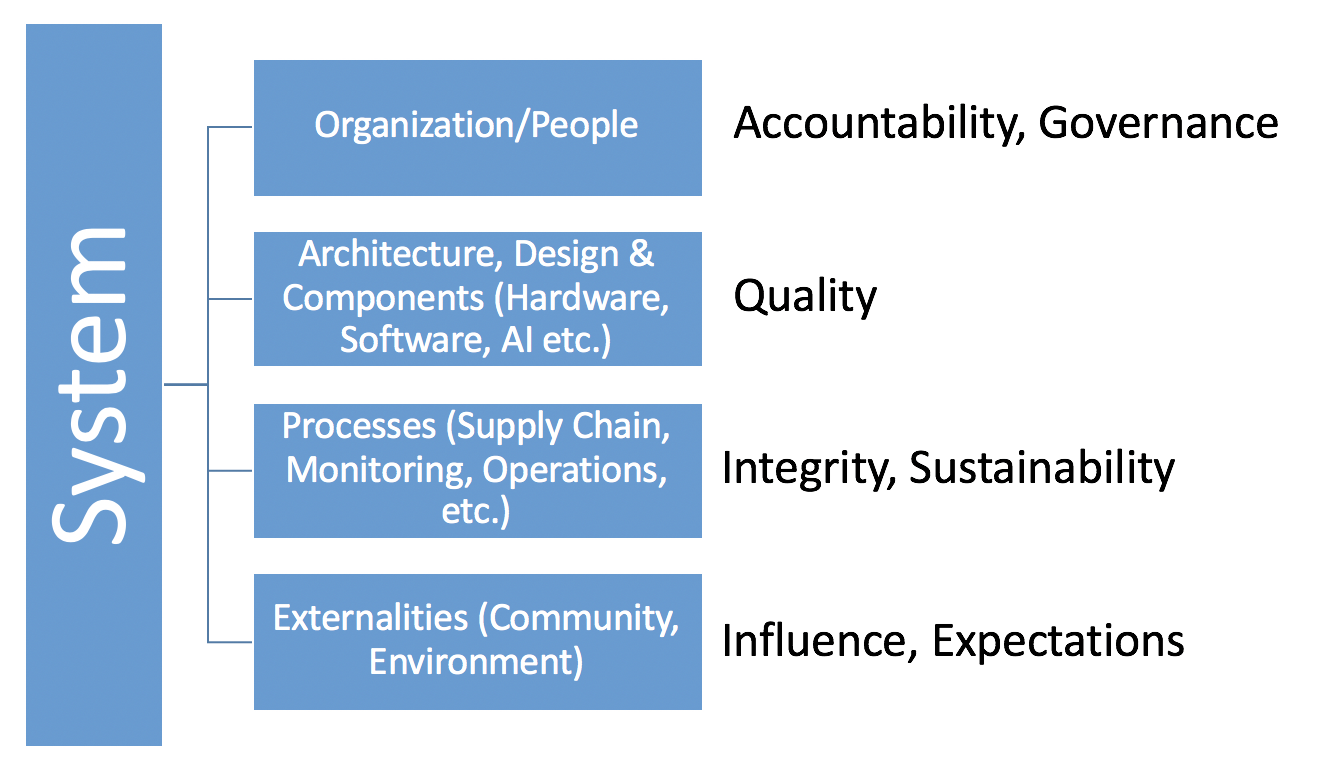
When thinking about trustworthiness it is not enough to think of the trustworthiness of a component, be it hardware or software or a technology like AI, since trust in the outcome and the consequences depend on the entire system. This system consists of the organization and people who have accountability and maintain governance, the architecture, design, and technologies which must have sufficient quality, and the processes used that relate to the integrity and sustainability of the system.
A system also includes the external environment and all that it entails, including expectations, influence, rules, regulations and so on. As an example, privacy expectations can influence whether a system is viewed as trustworthy.