As sensors proliferate the quantity and variety of data will become overwhelming and difficult to process efficiently and effectively. Information of value will be derived from multiple sensors, possibility of different types and with different creators and software. This situation will call for standardization for interoperability yet also require standardization that can scale and not require centralized management.
Adoption will also require simplicity and usability. Conceptually, providing an extensible annotation mechanism will allow arbitrary information to be associated with sensor information, shared and used in an open and extensible manner. The key idea is that rather than requiring every single sensor schema/data structure to define additional data formats or extension mechanisms, annotations can be added in a uniform manner at any time at any point in the processing flow with definitions of what the annotations are deferred until needed and used.
In some ways the Internet of Things may be like “web services” were envisioned earlier (e.g. WS*, SOAP etc): there will be multiple sources of information that will send messages that may be aggregated and correlated by intermediaries that may go on to be sources for further recipients. Ultimately there will be a sink to provide information to a “user”, although this may be a software application (not depicted in the diagram below). Annotations could serve as a interoperable means to associate semantic information. The following diagram [1] might represent this, though it was for a paper specifically about a specific sports monitoring application.

One can envision a world where sensors use annotations to provide meta-data associated with sensor data, such as providing calibration, sensitivity, location and environmental readings relevant to the core data of the sensor. One can also imagine web intermediaries adding annotations (e.g. weather data to associate with basic readings of a thermostat) or humans or others later adding annotations. All of this additional information can aid with the correlation and processing of the data. There are also numerous practical applications of annotations beyond sensors.
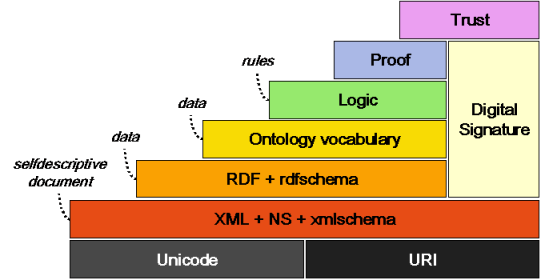
The web community has already defined widely-used core mechanisms such as HTTP and REST APIs, JSON, HTML5, etc that can be used to form a stack for sensor sharing. One aspect of this stack will be the need to share meaning of data, so that it can be combined and used by applications that offer more value. The semantic web community has worked for years to create a strong, flexible well-defined model including many needed aspects such as a powerful triple model and use of URLs for type definitions. Semantic web adoption has occurred behind the scenes but has not been very user-visible since some technologies are verbose and complicated (RDF) and some discussions tend to be obscure (e.g. debates about ontology theory). None of this takes away from the fact that there is a well-defined and tested infrastructure that has been analyzed and well developed.
The definition of a simple approach to associate JSON named values with triples (or quads) in the semantic web model through the inclusion of simple JSON definition files can be considered a breakthrough. This JSON-LD approach hides the entire semantic web mechanism from web developers and does not require the apparent explicit use of RDF, yet enables the full power of the semantic web to be used behind the scenes when information is processed, without burdening information creators (or creating large data traffic to represent the information). The following hides a richer model behind an easy to use syntax [2]:
<script type=”application/ld+json”>
{“@context”: “http://schema.org”,
“@type”: “Restaurant”,
“name”: “Fondue for Fun and Fantasy”,
“description”: “Fantastic and fun for all your cheesy occasions”,
“openingHours”: “Mo,Tu,We,Th,Fr,Sa,Su 11:30-23:00”,
“telephone”: “+155501003333”,
“menu”: “http://example.com/menu”}
</script>
This means that the semantic layer in the diagram above need not mean hard to understand and thus hard to adopt syntax, nor need it mean excessive syntax or message sizes creating a barrier to deployment.
The W3C Annotation Community Group has already created an Open Annotation Data Model that leverages the semantic web model to enable representation of a wide variety of annotation use cases, whether the annotation is of text, audio, video, raw data or what have you, while also enabling a wide variety of annotations on those targets. This flexible model is not required to use JSON-LD but I believe that JSON-LD will pave a way toward rapid adoption.
The W3C Web Annotation Working Group will produce standards to address these needs. This work is not from scratch but building on the previous work of the community group. As outlined in the Annotation Working Group charter, the deliverables will include key components needed to make annotations useful:
- Abstract Data Model: An abstract data model for annotations
- Vocabulary: A precise vocabulary describing/defining the data model
- Serializations: one or more serialization formats of the abstract data model, such as JSON/JSON-LD or HTML
- HTTP API: An API specification to create, edit, access, search, manage, and otherwise manipulate annotations through HTTP
- Client-side API: A script interface and events to ease the creation of annotation systems in a browser, a reading system, or a JavaScript plugin
- Robust Link Anchoring: One or more mechanisms to determine a selected range of text or portion of media that may serve as a target for an annotation within, in a predictable and interoperable manner, with allowance for some degree of document changes; these mechanisms must work in HTML5, and must provide an extension point for additional media types and formats
Take a look at the Web Annotation Architecture diagram.
Creating a layer in the stack to enable collecting and combining sensor information in a meaningful way will require the means to associate additional information with sensor data (data model and vocabulary), a means to share the model in a concrete representation (serialization), and application interfaces (APIs).
Sensors are only one area where open annotations will have value. There are many use cases, including annotations of e-books, web pages, audio, video, maps, portions of data sets and many more. Annotations are fundamental to human interaction and as I suggest in this blog also to automated systems such as those using sensors.
To learn more about the basis for the W3C Annotation WG effort see the W3C Workshop on Annotations report and the materials from the I Annotate conference.
[1] Combining Wireless Sensor Networks and Semantic Middleware for an Internet of Things-Based Sportsman/Woman Monitoring Application, Jesús Rodríguez-Molina,* José-Fernán Martínez, Pedro Castillejo, and Lourdes López in Sensors 2013. See https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3649371/
[2] See What is JSON-LD? A Talk with Gregg Kellogg by Aaron Bradley on September 10, 2014 and schema.org examples for location pages.


{kind=link}